JAVA 8入门(二)流
1.简单使用
书接上回,我们这一讲要讨论 JAVA 8 的新的 API 流。如果我们有这样一个需求,需要挑选出菜谱里面卡路里小于1000,且卡路里排名前三的菜品的名称。
如果使用JAVA 7的传统写法我们应该这样写:
1 | public List<String> findDish(List<Dish> menu){ |
通过上面的例子我们可以看到我们使用了很多的中间变量,来存储中介结果,lowCaloricDishes、result、resultName。相当繁琐。如果我们使用 JAVA 8的流的方式来实现代码是这样的:
1 |
|
如果我们把 steam() 变换为 parallelStream(),整个操作就变成并行的。代码十分优雅,想到每天我们处理那么多的集合,反正我已经迫不及待的想使用上`JAVA 8了。
2. 流的定义
到底什么是流?书上给的定义是 “从支持数据处理操作的源生成的元素序列”。
- 元素序列 和集合一样,我们可以理解为是一堆有序的值。但是集合侧重的是数据,流侧重的是计算。
- 源 流会使用一个提供数据的源。比如
menu.stream()中,meun就是这个流的源。 - 数据处理操作 流的数据处理功能类似,数据库的操作,同时也支持函数式编程中的操作。
我们看看接口java.util.stream.Stream都有一些什么方法:
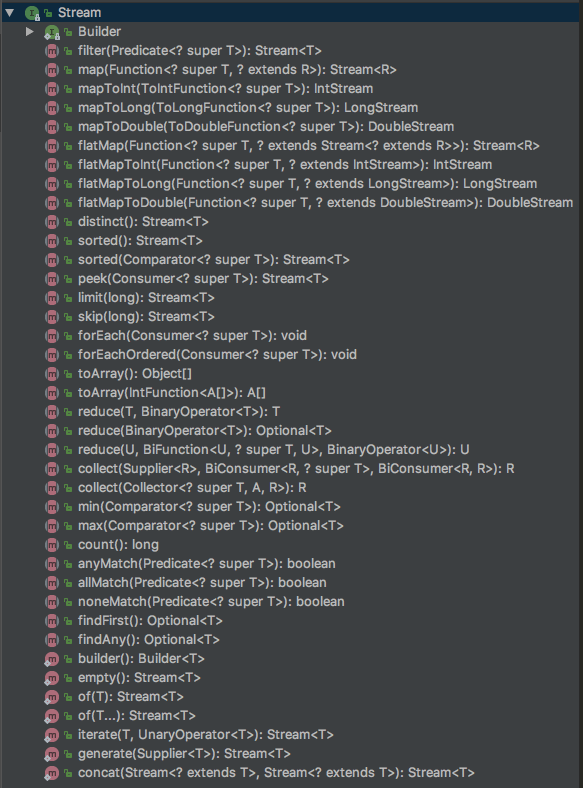
我们可以看到,之前我们在上一个例子里面使用的方法,filter(),sorted(),limit(),map() 的返回值也是一个流Stream,也就是说我们可以,把所有的操作串起来。这个是流的一个特点流水线
还有一个特点就是内部迭代,与集合的迭代不同,流的迭代不是显式的迭代。
3. 流的基本操作
1. 筛选和切片
筛选filter()
所谓筛选就是找出符合条件的元素,
filter()接受一个返回boolean类型的函数。
比如:1
filter(dish -> dish.getCalories()<1000)
去重distinct()
去重的方法我们可以类比
SQL语句中的 distinct截断limit()
同样类似
SQL里面的 limit,接受一个 Long 值。返回流中的前n个元素。跳过skip()
跳过前n个元素。很好理解
2. 映射
map()
map对流中的每一个元素应用函数,可以理解为将元素转化为另一个元素。
1
.map(Dish::getName)
flatmap()
flatmap方法就是把流中的每一个元素都装换为另外一个流,然后合并为一个流。
1
2
3
4
5
List<List<String>> lists = new ArrayList<>();
lists.add(Arrays.asList("apple", "click"));
lists.add(Arrays.asList("boss", "dig", "qq", "vivo"));
lists.add(Arrays.asList("c#", "biezhi"));
找出所有大于两个字符的元素:
1 | lists.stream() |
3. 查找匹配
match、anyMatch、allMatch、noneMatch
以上方法都能返回一个boolean类型。
1 | boolean hasLowCalories = mune.stream().anyMatch(dish -> dish.getCalories()<1000) |
4. 归约
reduce(T,BinaryOperator<T>)
reduce 操作是 反复结合每一个元素,直到流被归约成一个值。其中:
T指的是初始值;BinaryOperator<T>两个元素结合起来获得一个元素,举个例子:
Lamdba:(a,b)-> a + b。
所以给定一个 List<Integer> 计算出和所有int 的和:
1 | int sum = list.stream().reduce(0,(a,b)-> a + b); |
或者:
1 | int sum = list.stream().reduce(0,Integer::sum); |
5. 收集数据
一顿操作之后,我们需要把数据收集起来。就需要使用collect()方法。
1 | Map<String, Integer> map = meun.stream() |